
Data Mesh — A new Level of Data Collaboration using Self-Serve Analytics (Subscribe Process)
Self-Serve Analytics — The Subscribe Process
Now that the data product is in a discoverable state its time we talk about the subscribe process. The subscribe process can be broken down in two main parts:
– Data consumers start by discovering data products based on search criteria followed by sending subscription requests to the data publishers.
– Data producers review subscription requests and approve/deny subscription requests.
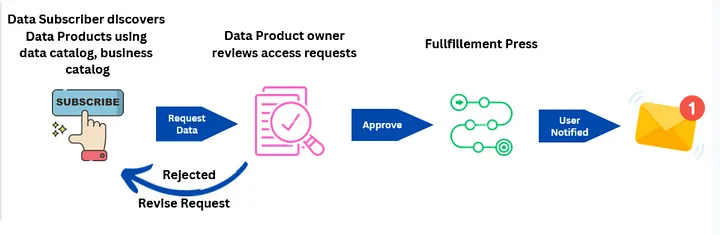
At the start data consumers start the process by discovering data products by entering search term in one of the search boxes.

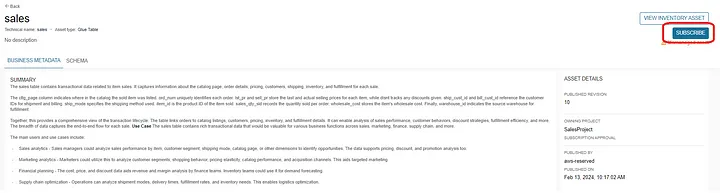
Data consumers make a choice of data products by going through he business glossaries , schema details and metadata forms. Once comfortable with their choice they subscribe to the chosen data product.
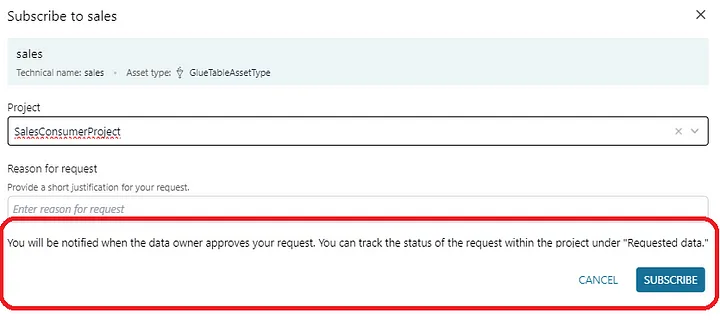
Data consumers enter a valid reason and complete their request by pressing the Subscribe button. This action ends up sending a notification to the data producer.
Data producer reviews the incoming subscription requests and proceeds to view the request as under.
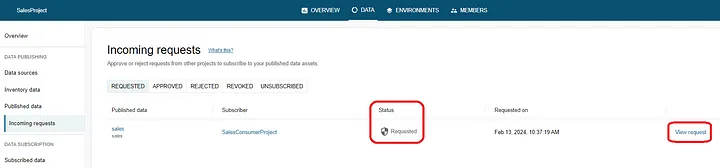
At this point the data producer may proceed by either approving or denying the request.
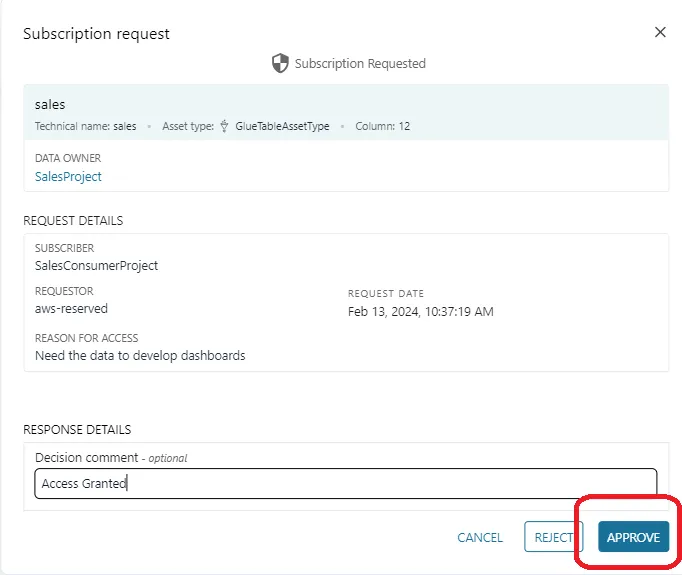
Once approved the data producer may choose to revoke the request any tie in the future. This feature comes in handy in case the consumer requires only temporary access to a particular data product.
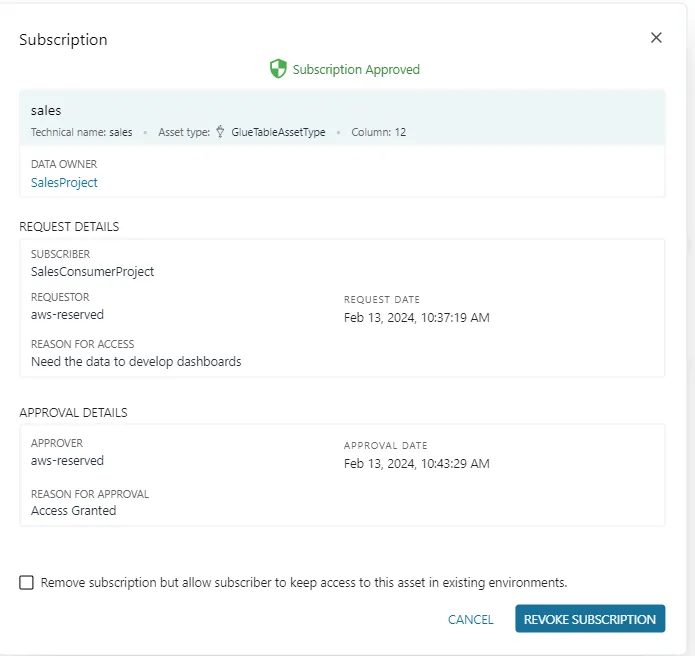
The subscription process is now complete. It’s time to start interacting with data that the subscriber has access to.
Self-Serve Analytics — The Fulfillment Process
Once the data consumer has been provided access they may access it using Amazon Athena or Amazon Redshift query editor. The fulfillment process takes cares of this by creating soft links to data product using AWS LakeFormation. In other words, AWS LakeFormation adds the necessary governance by adding a layer of access policies and fine grained access control.
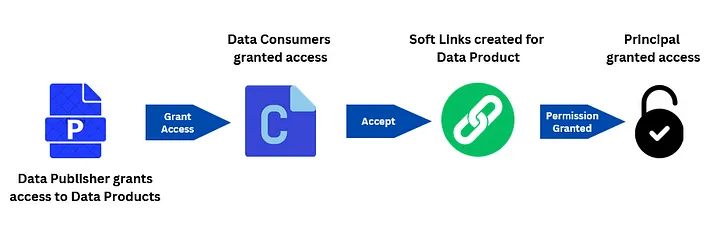
You might have noticed by now that the publish, subscribe and fulfilment process requires minimal support by the IT teams. This exactly why it is referred to as “self-serve analytics”.
I hope this article helped understand how the creation of the data meh promotes collaboration between data driven teams. Topics like these are covered as part of the AWS Data Analytics course offered by Datafence Cloud Academy.

