
Data Mesh — A new Level of Data Collaboration using Self-Serve Analytics (Publishing & Discover)
In this article, we will learn how Amazon DataZone promotes the idea of “self-serve data analytics”. by simplifying the data collaboration process. Learn how to publish, discover, subscribe, govern, & share data products using Amazon DataZone.
Over the last few years, organizations have been busy creating data assets that are critical for decision-making processes. However before the decision-making process kicks in, these data assets must be securely shared within the right governance in place. In addition to that, several organizations are planning revenue diversification through data monetization. But this dream cannot be effectively realized without having tight data-sharing protocols in place.
Traditionally for sharing data purposes, organizations have relied on mechanisms such as tables, data lakes, databases, warehouses, emails, SFTP, APIs, cloud storage, and network shares.
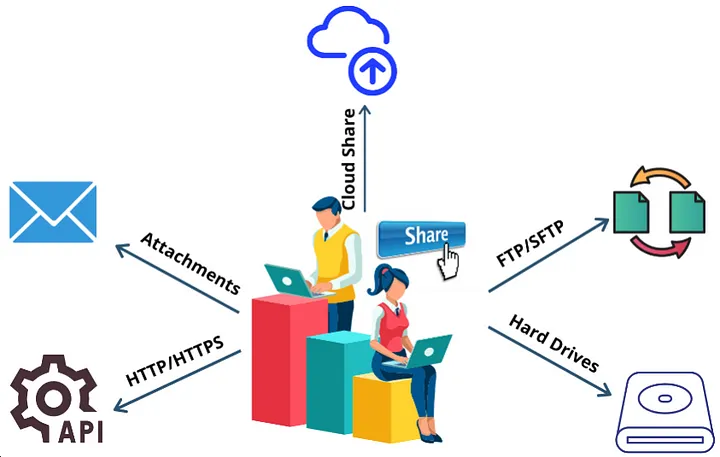
Problems associated with Traditional Data Asset Distribution
Unfortunately, there are several problems related to these data-sharing methods:
– Complex: These data distribution mechanisms can be complex to set up and use because they may require exchanging keys/passwords and using a variety of different tools.
– Insecure: These mechanisms may not be secure for data-at-rest or data-in-transit. This means the classic man-in-the-middle attack could expose data in clear text.
– Tracking & Lineage: There is no clear method available for effectively tracking who shared data with whom and using which mechanism.
– Control: You can’t control over who is using the shared data.
– Updates: Sharing data is a continuous process, and using the mechanisms mentioned previously does not provide a simple way to share updates.
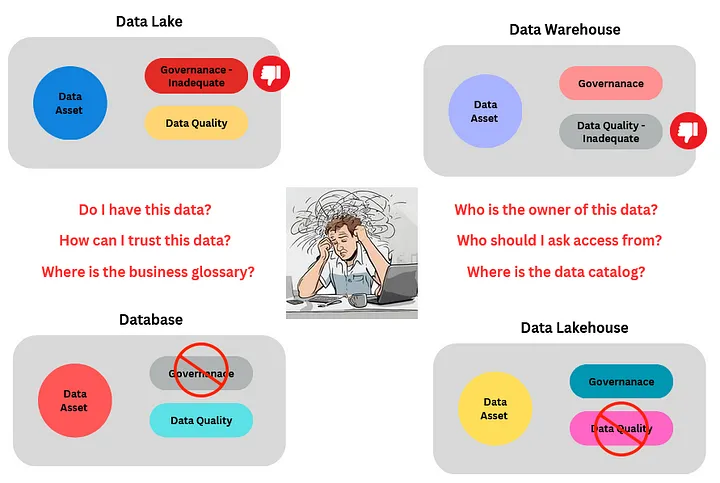
– Data Quality: The data asset in use may have questionable data quality.
– Business Glossary: Data is missing it’s meaning, which means there isn’t an adequate data or business catalogue/glossary.
Typical Data Distribution Process
The following diagram summarizes how a data asset is typically distributed within an organization.
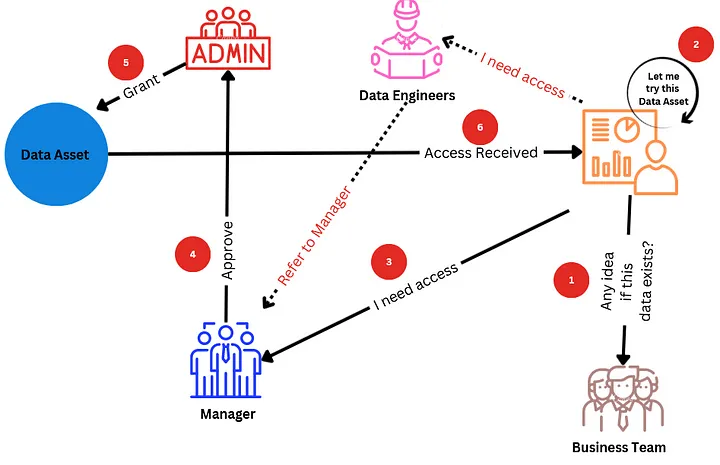
The traditional data distribution process is complex and consumers need to go through multiple steps. This ends up aggravating end consumers as well as wasting a lot of time.
The Paradigm Shift for Data Distribution — Data Mesh
Data Mesh is a framework that distributes data products. The core idea of the data mesh is the seamless delivery of high-quality data products in a reasonable amount of time with the highest level of governance control possible.
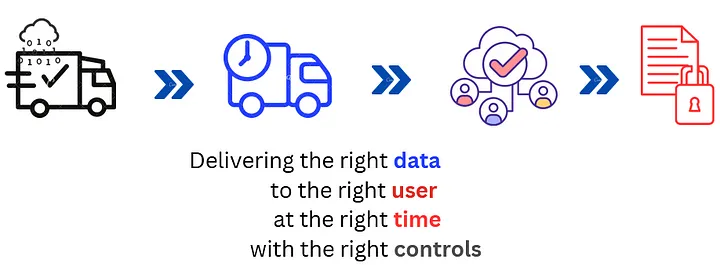
Data Mesh — Centralized Governance Decentralized Access
The core idea of the Data Mesh is to centralize the data governance process but decentralize the data access.
The following are a few benefits of implementing a Data Mesh:
– Simplified Data Collaboration — Seamless links producers and consumers of data products.
– Promote Self-Serve Analytics — Data product distribution driven using self-serve portals.
– Federated Governance — Centralized data governance.
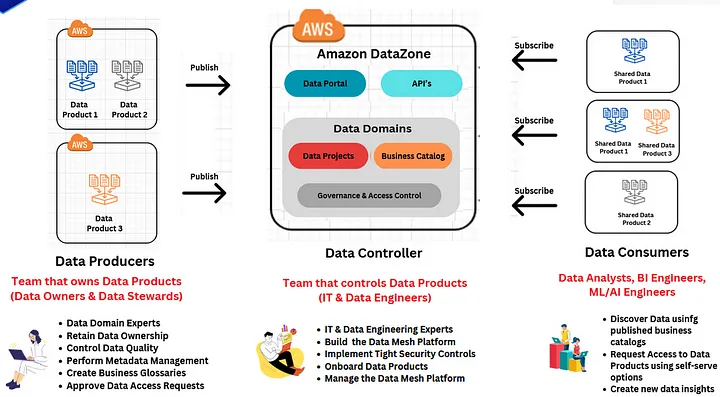
A Data Mesh is comprised of the following layers:
– Data Producers: Data producers are data domain experts. They act as data product owners who oversee the lifecycle of the data product from improving the quality of data, adding business glossaries, performing metadata management, and finally approving data requests.
– Data Controllers: Data controllers are IT experts such as cloud administrators and data engineers who are responsible for creating the data mesh platform, implementing tight security standards, and maintaining the data platform.
– Data Consumers: Data consumers discover data products using published catalogues, and create valuable data insights by subscribing to data products.
Amazon DataZone is a data management service that makes the creation of Data Mesh faster and easier for customers. Using Amazon DataZone you can easily create business catalogues, discover, share, and govern data stored across AWS.
Understanding the Data Mesh Process — Self-Serve Analytics
These days there is a lot of buzz around “self-serve analytics”. In an ideal analytics world, consumers of data such as BI, ML, and AI engineers should be entirely focused on deriving results from data, and not acquiring, enhancing, or improving its quality.
Traditionally, IT experts have played an instrumental role in data acquisition, enhancement, and distribution. Although it has been a workable solution, it lacks certain efficiencies. IT experts do not understand the intricacies of business so how can they be the best group to make business-related decisions?
Data Mesh aims at building a self-driven data management process that is capable of putting controls in the hands of people who understand it the most.
Amazon DataZone implements the Data Mesh using three critical processes:
– Publish Process — During this process, the data owner/steward publishes data products by connecting to the source, adding business glossaries, and enhancing metadata.
– Subscribe Process — During this process, the data consumers discover data products and if found useful subscribe to them.
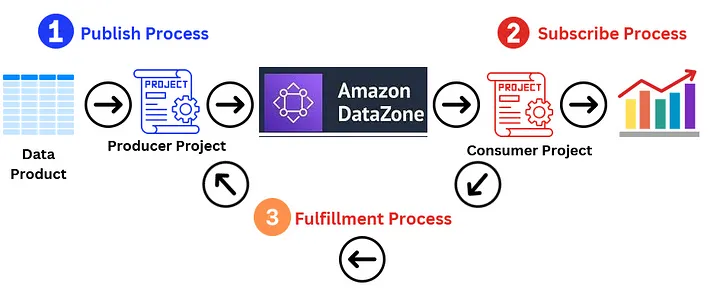
– Fulfilment Process — During this process, data products are made available to consumers using symbolic links to data sources.
Self-Serve Analytics — The Publish Process
The process of publishing data starts by the data producers (typically data owner or data stewards) creating a data product from previously configured data sources. Once the data product has been created the data publisher proceeds towards data enhancement. Data enhancement is a combined term for adding business glossaries, metadata management, and schema discovery.
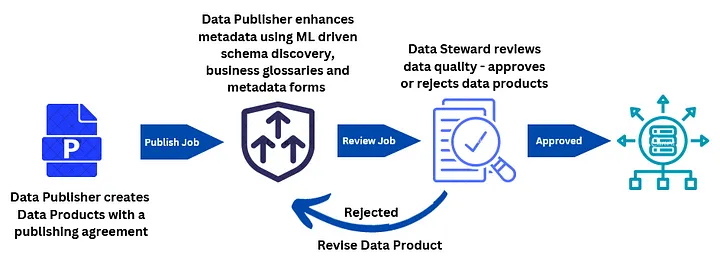
The data enhancement process can optionally go through a review cycle where it can either be rejected or approved for final publishing.
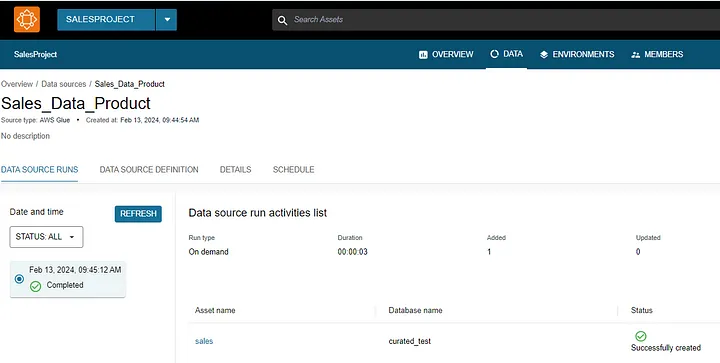
Let’s try to understand the publish process using some screenshots from Amazon DataZone. The following image below shows a data product named “sales” that originally exists in the “curated_test” database of the glue catalogue.
Once the data product has been added to Amazon DataZone, the data producer can add business metadata to it. The “Generate Description” is a generative AI feature (powered using Amazon Bedrock) in Amazon DataZone to automatically generate descriptions.
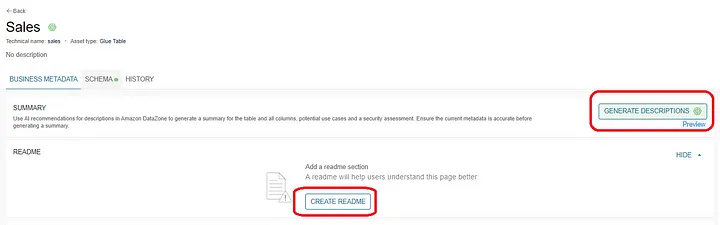
Once the generative AI has successfully generated the descriptions you may choose to either edit, accept, or reject them. Notice that the Asset Details section below shows further metadata regarding the data product.
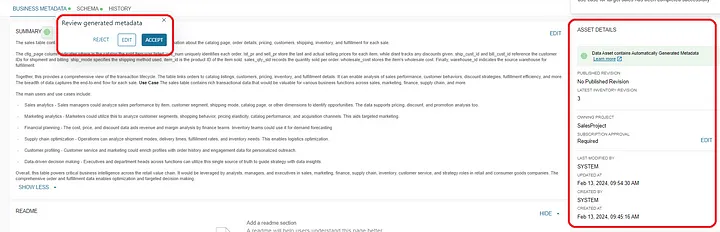
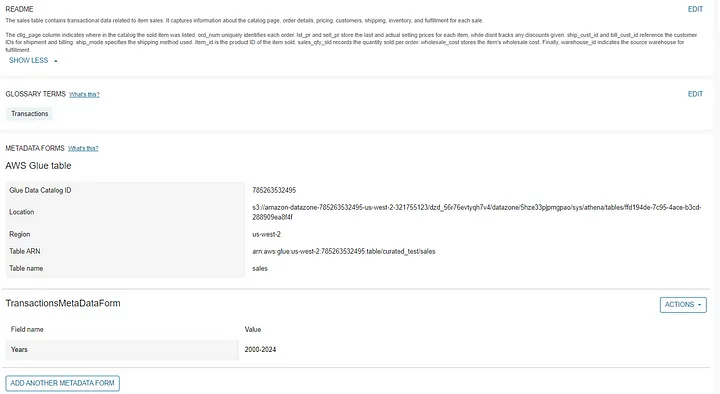
As part of data enhancement the data producers may add a “Readme” as well. Notice that Amazon DataZone stores some additional metadata related to data location and table name.
Optionally you may add metadata forms to further enhance your data product. This is done by creating metadata form with user-defined fields.
In the case below, I have chosen to add a metadata form that stores a field called “Years” to depict the range of years in the sales data product.
Moving on the schema, the generative AI feature also adds description for every column as well as makes the column names appear more human readable. As I mentioned before the data producer may choose to approve or reject any text generated using the AI feature.
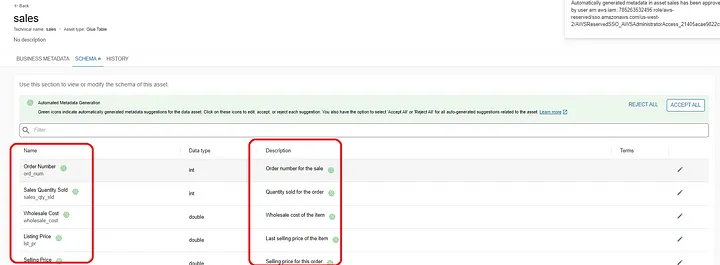
Once the data producer feels that the data product is ready they may proceed to approve the data product at which time it becomes discoverable for the consumers of data.

